Our work on exploting secondary latent features for task grouping got accepted for oral presentation in ICMR 2019 in Ottawa, Canada. This paper introduces Selective Sharing, a method using the factorized gradients per task as a signal that helps in grouping tasks that benefit eachother’s learning process. The grouping is conditioned on a predefined metric so different strategies can be explored. We are preparing the repo for the code release and the site will be updated with a link to the official proceedings.
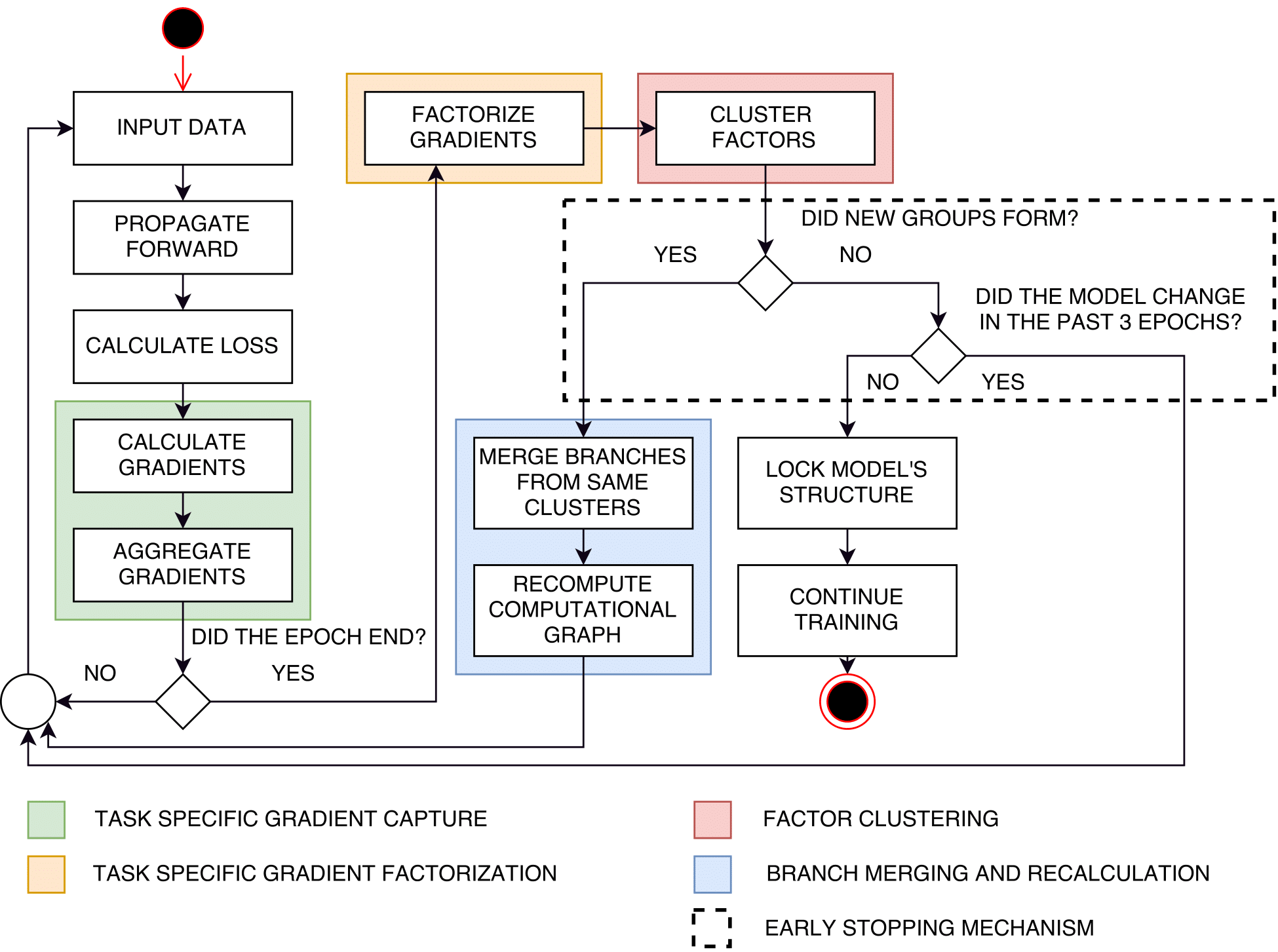
The figure below illustrates a high level overview of the Selective Sharing architecture. All tasks share the same input data (purple) and pass through the same feature extraction block before arriving to the shared representation (blue block). From the final shared representation all tasks branch in identical estimators with a different output (per task). With each mini-batch we accumulate gradients and factorize them. After clustering the factorized gradients from the set of tasks, the architecture is recomputed to group tasks whose gradients belong to the same factor cluster which implies keeping one estimator and discarding the rest so that the group tasks would only differ in their output.
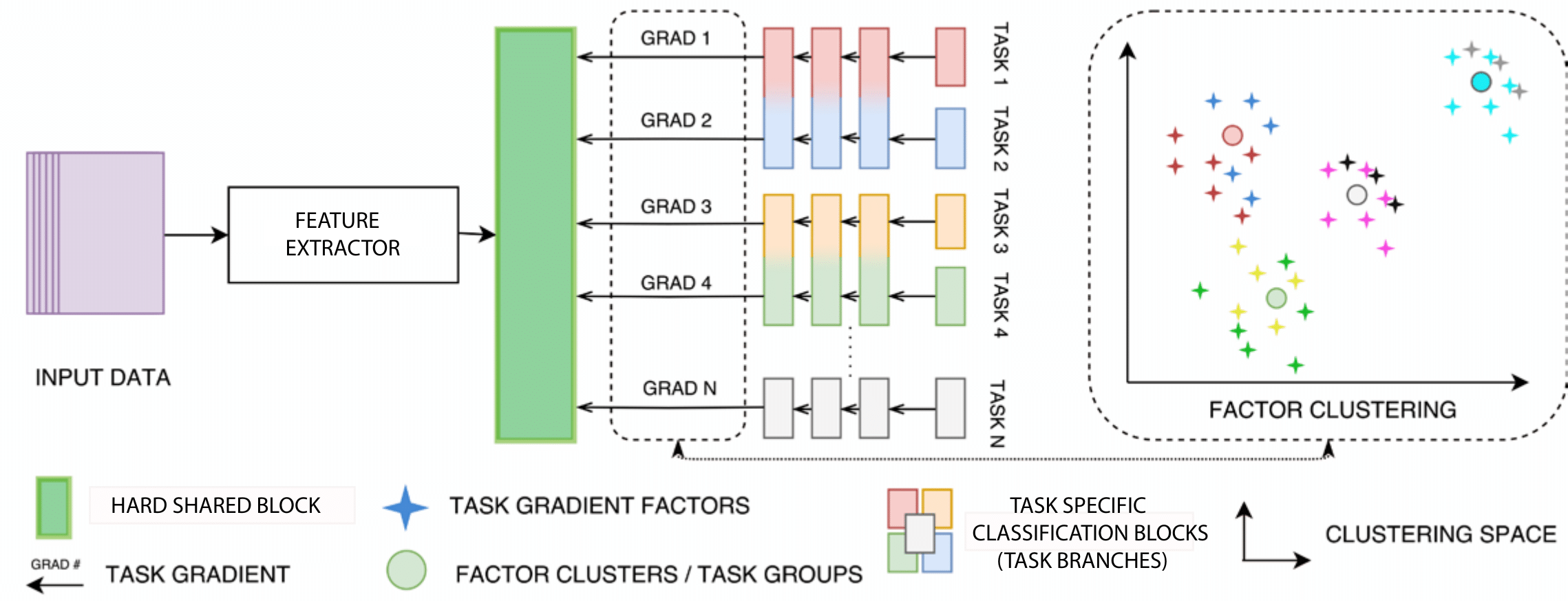
Multimedia applications often require concurrent solutions to multiple tasks. These tasks hold clues to each-others solutions, however as these relations can be complex this remains a rarely utilized property. When task relations are explicitly defined based on domain knowledge multi-task learning (MTL) offers such concurrent solutions, while exploiting relatedness between multiple tasks performed over the same dataset. In most cases however, this relatedness is not explicitly defined and the domain expert knowledge that defines it is not available. To address this issue, we introduce Selective Sharing, a method that learns the inter-task relatedness from secondary latent features while the model trains. Using this insight, we can automatically group tasks and allow them to share knowledge in a mutually beneficial way. We support our method with experiments on 5 datasets in classification, regression, and ranking tasks and compare to strong baselines and state-of-the-art approaches showing a consistent improvement in terms of accuracy and parameter counts. In addition, we perform an activation region analysis showing how Selective Sharing affects the learned representation. A complete overview of how Selective Sharing works can be seen in the Figure below.
In any deep learning system, gradients flow from the final layers of the model towards the starting ones carrying a corrective signal for the weights and biases along the way. They are a way for the model to know where and how much it should correct its trainable parameters. Selective Sharing is based on the assumption that the identically constructed task specific estimators, sharing the same input and feature extraction platform, would manifest a correlation between the back-propagated gradients for related tasks.
The name Selective Sharing is derived from an important property of the method itself, which is allowing the model to select the tasks where sharing should occur, without it being specifically programmed to do so. There is however, a general directive for the sharing. The directive is given before the model training starts and is essentially the clustering condition. Depending on the goal the model can perform sharing by:
Selective Sharing is a multi-task learning approach for images in context that allows exploiting task relatedness for group formation without any predefined intertask dependency. Group formation is performed using conditional statements on distances between clusters of task specific gradient factors. This grouping procedure implicitly reduces the trainable parameter space dimensionality and boosts predictive performance for related tasks (or contextual attributes) as a result. Moreover, Selective Sharing is modality invariant, making it applicable in every multimedia scenario where a supervision signal and multiple targets are available. As such, applied on a wide range of MTL problems, Selective Sharing adjusts the representation learning process to implicitly exploit the entanglement between the contextual attributes and supports learning robust shared representations.
On a general note, experimental results on images in context show that forming groups of tasks over which we build a mutual representation is beneficial to the overall learning process. Figure 6 illustrates that the features we obtain are more robust and general in comparison to STL and MTL baselines. Furthermore, the way a model defines its groups, affects the performance in specific ways. E.g. sharing with similarity can improve tightly interconnected tasks, but sharing with variance can improve the overall performance as the latent data representation is built with respect to more contextual attributes that correlate and hold exclusive data insight. Compared to conventional matrix driven MTL approaches, Selective Sharing provides an additional degree of freedom in modeling the tasks at hand, as between task relations need not be studied prior to the classification architecture design. Moreover, the intuition and logic behind the approach is simple and easy to grasp without the need for complex mathematical or statistical apparatus, making Selective Sharing a versatile and useful approach to MTL. Conclusively, sharing is a virtue and knowing who to share with - is awareness. We attempt to teach our models how to do both.